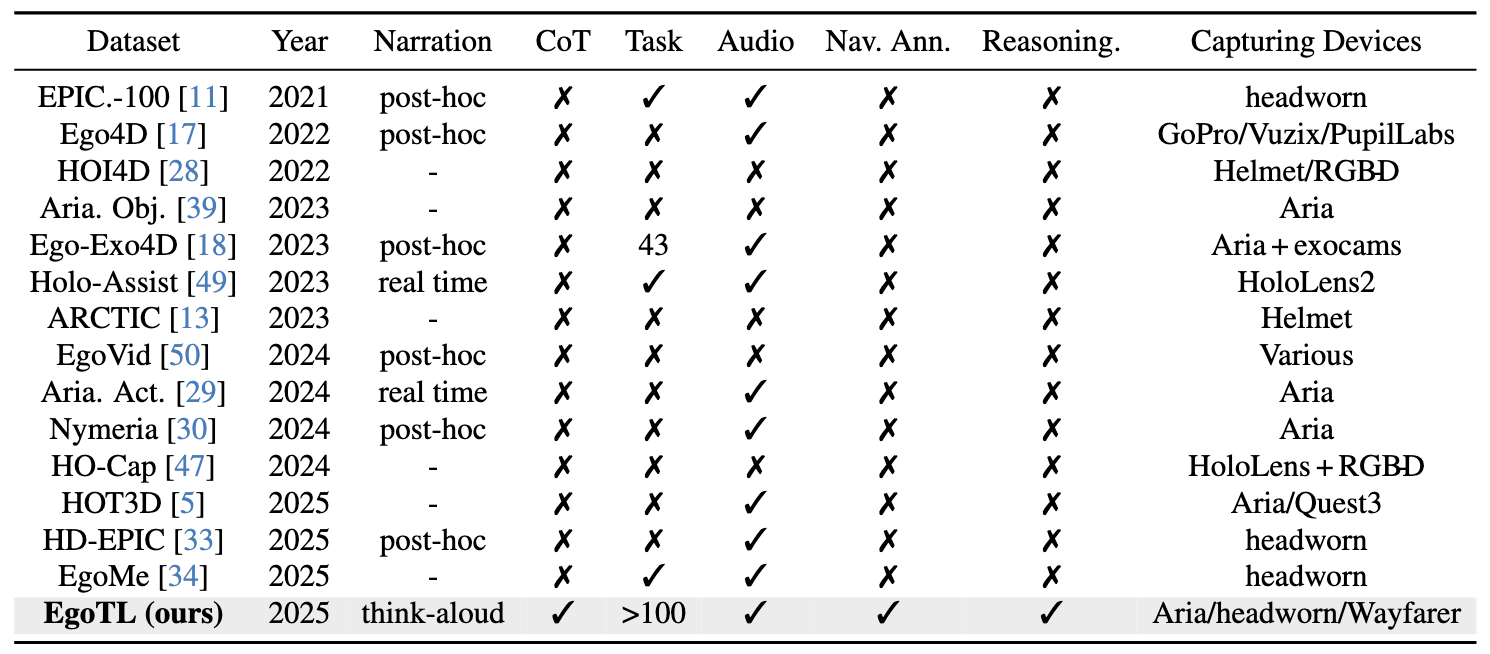
✨ EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks ✨
Abstract
Large foundation models have made significant advances in embodied intelligence, enabling synthesis and reasoning over egocentric input for household tasks. However, VLM-based auto-labeling is often noisy because the primary data sources lack accurate human action labels, chain-of-thought (CoT), and spatial annotations; these errors are amplified during long-horizon spatial instruction following. These issues stem from insufficient coverage of minute-long, daily household planning tasks and from inaccurate spatial grounding. As a result, VLM reasoning chains and world-model synthesis can hallucinate objects, skip steps, or fail to respect real-world physical attributes. To address these gaps, we introduce EgoTL. EgoTL builds a think-aloud capture pipeline for egocentric data. It uses a say-before-act protocol to record step-by-step goals and spoken reasoning with word-level timestamps, then calibrates physical properties with metric-scale spatial estimators, a memory-bank walkthrough for scene context, and clip-level tags for navigation instructions and detailed manipulation actions. With EgoTL, we are able to benchmark VLMs and World Models on six task dimensions from three layers and long-horizon generation over minute-long sequences across over 100 daily household tasks. We find that foundation models still fall short as egocentric assistants or open-world simulators. Finally, we finetune foundation models with human CoT aligned with metric labels on the training split of EgoTL, which improves long-horizon planning and reasoning, step-wise reasoning, instruction following, and spatial grounding.
Compare your spatial intelligence abilities with latest GPT!
Watch the egocentric video, answer the question, then reveal the ground truth and GPT's answer.





Memory Planning Task 1: Plan a route from memory
This video is playing at 1x speed. You can adjust the speed using the controls above.
Question: My abstract task is to grab the banana in the kitchen. Based on the memory-bank video, which option should I choose if I start from the living room?
Options:
Ground Truth: A GPT: B
👉 Click to view Ground Truth and GPT's answer!
Action Reasoning under Complex Env Task 2: Which action should be taken under the current frame?
Question: My abstract task is to grab the milk from the fridge. Which action should be taken under the current frame?
Options:
Ground Truth: B GPT: A
👉 Click to view Ground Truth and GPT's answer!
Next Action Prediction Task 3: What happens next?
This video is playing at 1x speed. You can adjust the speed using the controls above.
Question: After the doing the actions in video clip, what is the most likely next action?
Options:
Ground Truth: B GPT: C
👉 Click to view Ground Truth and GPT's answer!
Action Recognition Task 4: What is the subject doing?
This video is playing at 1x speed. You can adjust the speed using the controls above.
Question: Which description best matches the main action in this clip?
Options:
Ground Truth: D GPT: A
👉 Click to view Ground Truth and GPT's answer!
Direction Recognition Task 5: Which Direction?
This video is playing at 1x speed. You can adjust the speed using the controls above.
Question: In the video clip, which direction does it move?
Options:
Ground Truth: B GPT: C
👉 Click to view Ground Truth and GPT's answer!
Distance Estimation Task 6: How far apart?
This video is playing at 1x speed. You can adjust the speed using the controls above.
Question: Approximately how far, in meters, does the person walk in this video clip?
Ground Truth: 3.98 m GPT: 0.95 m
👉 Click to view Ground Truth and GPT's answer!
EgoTL-Bench Overview
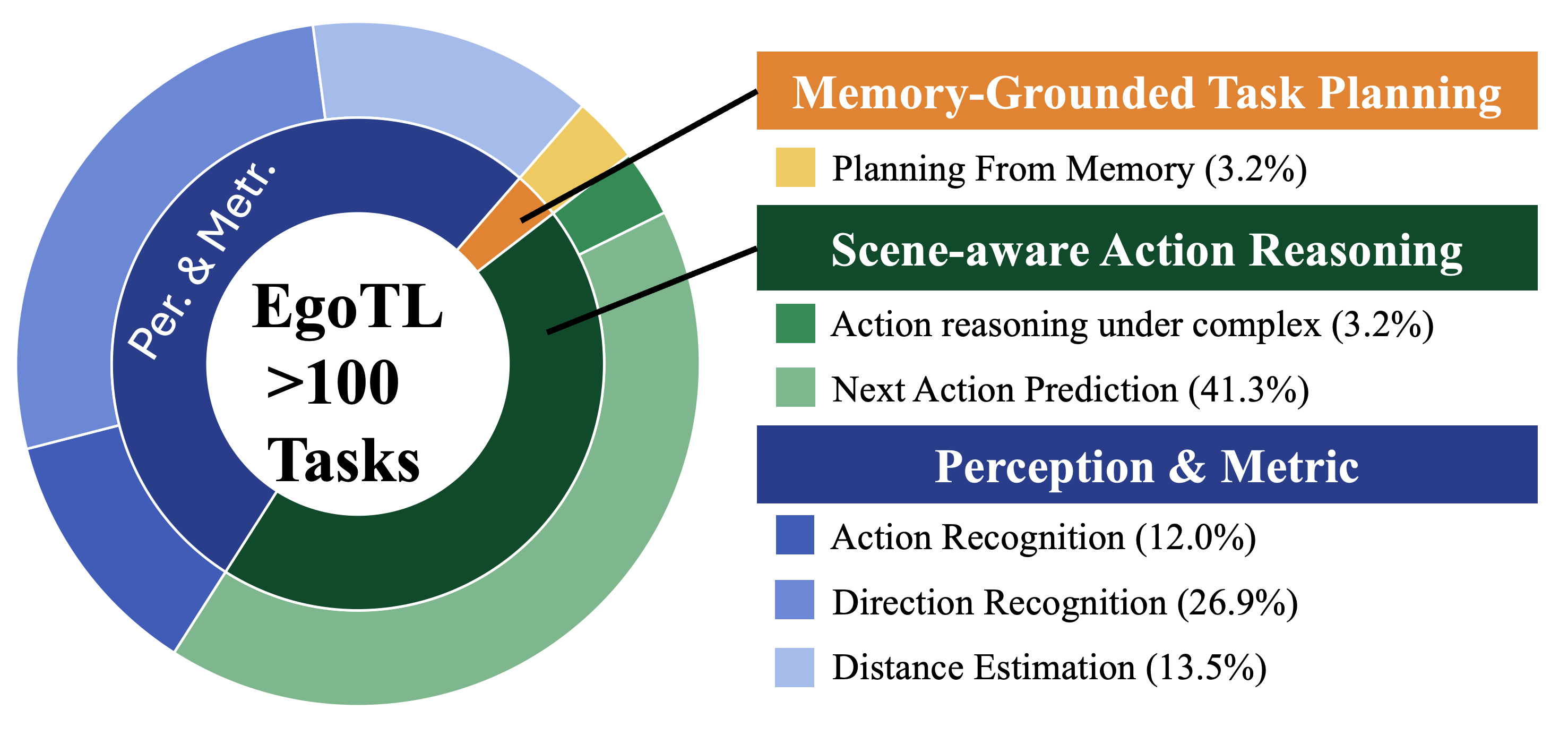
Benchmark Overview: EgoTL-Bench decomposes egocentric spatial understanding into six tasks across three layers. Memory-conditioned planning asks the model to generate an action plan from a memory-bank walkthrough and a high-level goal. Scene-aware action reasoning tests whether it selects the correct action in cluttered scenes, such as moving an obstacle before opening a door. Next action prediction checks if the model can infer the immediate next step from the current frame and abstract task. At the perceptual layer, action recognition describes the ongoing manipulation, direction recognition identifies egocentric motion primitives (walking straight, turning, standing or sitting), and distance estimation predicts how far the subject walks in meters. The shown examples are simplified; the full benchmark uses more templates, distractors, and longer episodes.

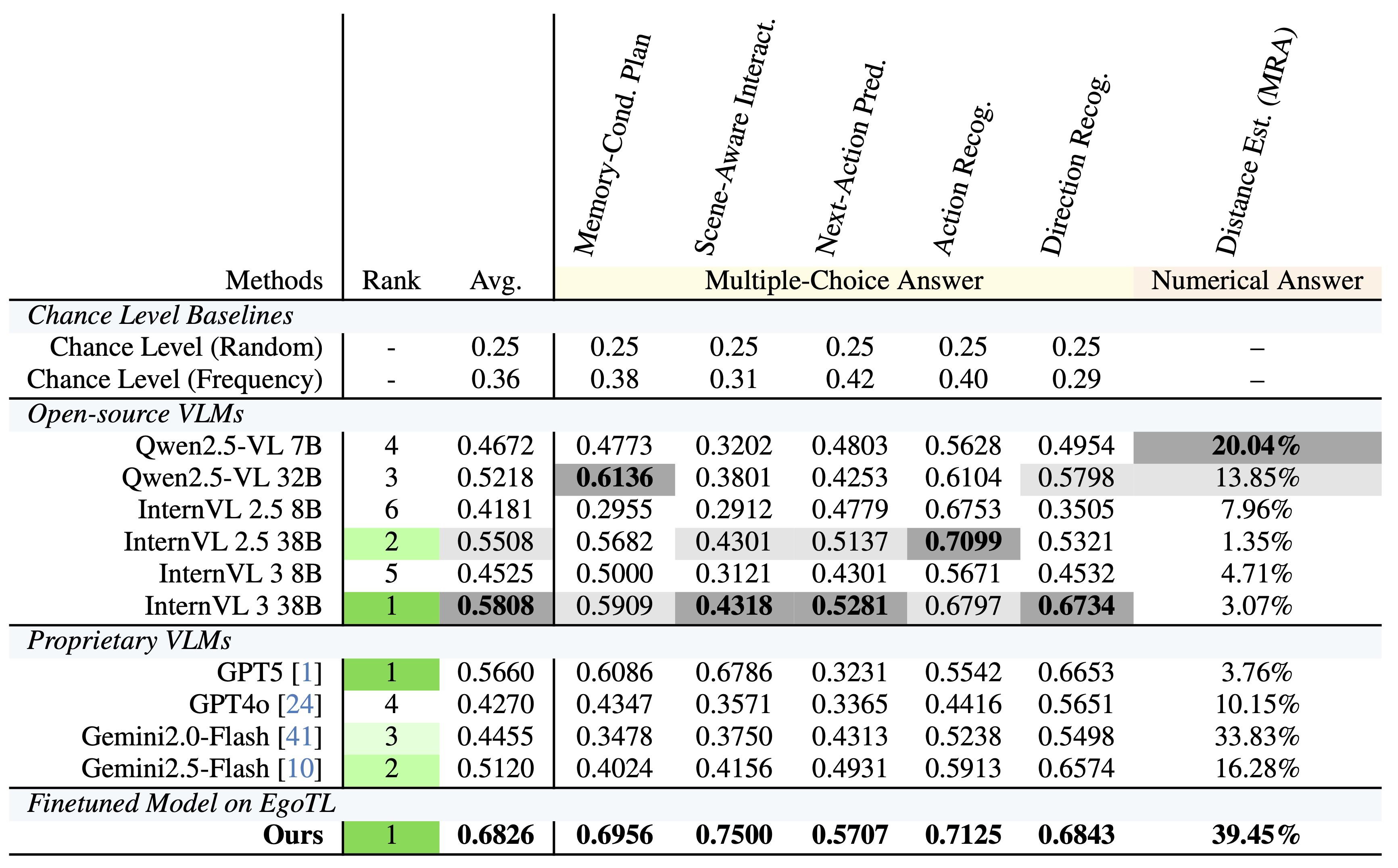
Evaluation Summary: EgoTL-Bench evaluates large foundation models on long-horizon egocentric reasoning with six tasks from three layers: memory-conditioned planning, scene-aware action reasoning, and perceptual-metric understanding. We report two chance-level baselines, compare open-source and proprietary VLMs, and include an EgoTL-finetuned model. Multiple-choice tasks are measured with accuracy, while distance estimation uses mean relative accuracy (MRA). We also evaluate world models on 60-second CoT-conditioned rollouts using CLIP-Score and VBench. Overall, current foundation models still lag in robust long-horizon spatial grounding, while EgoTL-based finetuning improves planning, step-wise reasoning, and rollout consistency.
Long-Horizon Video Generation: Modern world models can produce visually coherent short-horizon predictions, but on long-horizon egocentric tasks in EgoTL their rollouts quickly drift from the underlying 3D scene and intended plan: object size and position change over time, occlusions are inconsistent, and the camera may jump between rooms instead of following a continuous path. Even when individual frames remain photorealistic, the sequences often violate basic spatial constraints (room connectivity, landmark layout, object reachability), leading to trajectories that look locally reasonable yet fail to reach the final goal or handle obstacles correctly. These observations suggest that current long-horizon generative models lack an explicit egocentric spatial backbone, and that maintaining a consistent 3D cognitive map over hundreds of frames is essential if world-model-based agents are to support reliable navigation and manipulation in real homes.

BibTeX
@article{liu2026egotl,
title={EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks},
author={Lulin Liu and Dayou Li and Yiqing Liang and Sicong Jiang and Hitesh Vijay and Hezhen Hu and Xuhai Xu and Zirui Liu and Srinivas Shakkottai and Manling Li and Zhiwen Fan},
journal={arXiv preprint arXiv:XXXX.XXXXX},
year={2026},
url={https://arxiv.org/abs/XXXX.XXXXX}
}